Vi har nu spist tre frokoster med tre forskellige kødprodukter. Det er tid til at sammenligne de tre produkter i forhold til næringsindhold. Nedenstående tabel viser detaljerne for hver 100 gram af kødprodukterne. Daglig Bruger er altædende og prøver at følge en sund kost. Derfor er vi meget interesserede i, hvad vi spiser, og vi kan se, at der er markante forskelle mellem produkterne vi har prøvet.
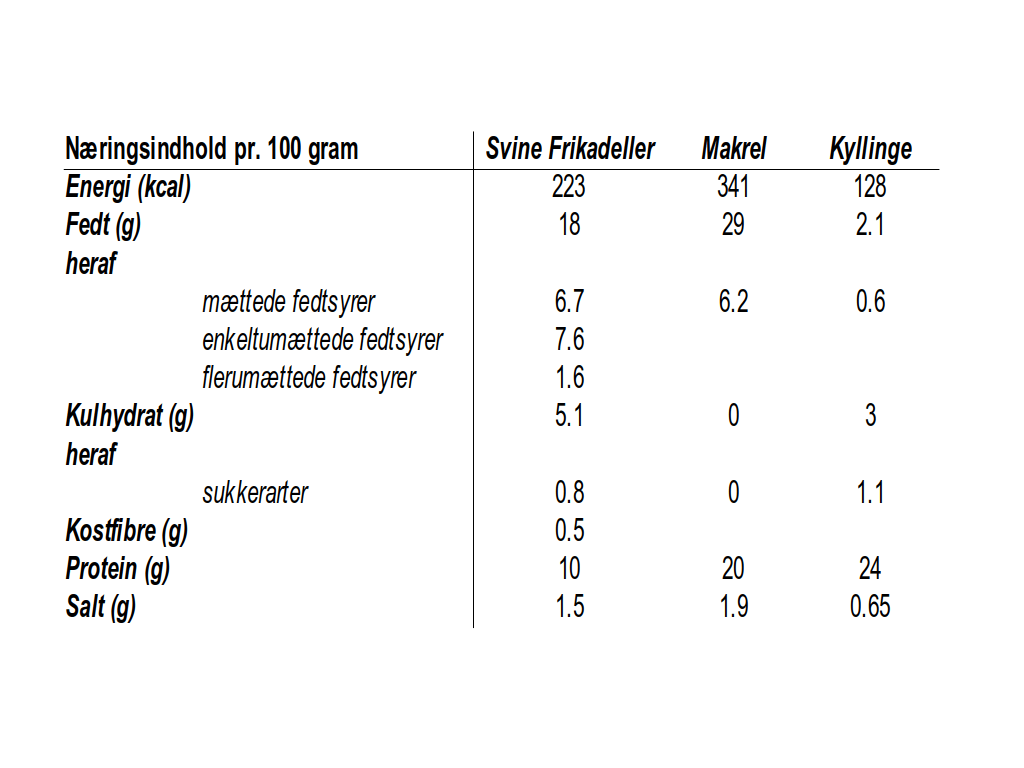
Makrelkød har det højeste energiindhold målt i kcal. Det stammer sandsynligvis fra den store mængde fedtsyrer, fiskekødet indeholder. Makrel fedtsyrer er også for det meste umættede, da kun 6,2 g af 29 g er mættede fedtsyrer. Vi også bemærker at makrelkød indeholder de gavnlige omega-3 fedtsyrer, som også er kendt som flerumættede fedtsyrer (læs mer fra Wikipedia).
Makrelkød har også dobbelt så meget protein som frikadeller, men en smule mindre protein sammenlignet med kylling. Makrelkød har det højeste salt indhold med 1.9g salt per 100g kød.
Kyllingekød er næsten kun protein fordi der er ikke meget fedt, kulhydrater eller salt. Man kan godt sige, at kyllingekød er en sund kødvariant at valge, hvis man kun søger efter ren protein kilde.
Frikadeller er det eneste færdiglavede fødevareprodukt i vores frokostkurv, og det viser sig også på næringsindholdet. Proteinindholdet er kun 10g, mens to andre produkter har mindst dobbelt så meget protein. Frikadeller har også en høj mængde mættet fedt sammenlignet med de to andre produkter. I forhold til saltindhold ligger frikadeller omkring imellem de to yderpunkter.
Alt i alt viser dette, at vi har designet en frokostkurv, der er ret varierende i sit næringsindhold. Dette er også en del af designet af frokostkurven, så ingen store overraskelser her. Ikke et dårligt slutresultat for vores altædende Daglig Bruger, der også prøver at spide sund mad.
(Billedet brugt i artiklen var ikke genereret af AI, men indholdet og idéerne er menneskeskabte i samarbejde med AI.)

